

You must log in or # to comment.
deleted by creator
Don’t forget to glue it all together at the end. Real chefs use epoxy
No, no, you are supposed to eat the glue.
Looks like I picked the wrong week to stop sniffing glue.
¯\_(ツ)_/¯
To make a pie, you’ll need a pastry crust, a filling, and a baking dish. Here’s a basic guide:
Ingredients:
For the pie crust:
2 1/2 cups all-purpose flour
1 teaspoon salt
1 cup (2 sticks) unsalted butter, cold and cut into small pieces
1/2 cup ice water
For the filling (example - apple pie):
6 cups peeled and sliced apples (Granny Smith or Honeycrisp work well)
1/2 cup sugar
1/4 cup all-purpose flour
1 teaspoon ground cinnamon
1/2 teaspoon ground nutmeg
1/4 teaspoon salt
2 tablespoons butter, cut into small pieces
Instructions:
- Make the pie crust:
Mix dry ingredients:
In a large bowl, whisk together flour and salt.
Cut in butter:
Add cold butter pieces and use a pastry cutter or two knives to cut the butter into the flour mixture until it resembles coarse crumbs with pea-sized pieces.
Add water:
Gradually add ice water, mixing until the dough just comes together. Be careful not to overmix.
Form dough:
Gather the dough into a ball, wrap it in plastic wrap, and refrigerate for at least 30 minutes.
- Prepare the filling:
Mix ingredients: In a large bowl, combine apple slices, sugar, flour, cinnamon, nutmeg, and salt. Toss to coat evenly.
- Assemble the pie:
Roll out the dough: On a lightly floured surface, roll out the chilled dough to a 12-inch circle.
Transfer to pie plate: Carefully transfer the dough to a 9-inch pie plate and trim the edges.
Add filling: Pour the apple filling into the pie crust, mounding slightly in the center.
Dot with butter: Sprinkle the butter pieces on top of the filling.
Crimp edges: Fold the edges of the dough over the filling, crimping to seal.
Cut slits: Make a few small slits in the top of the crust to allow steam to escape.
- Bake:
Preheat oven: Preheat oven to 375°F (190°C).
Bake: Bake the pie for 45-50 minutes, or until the crust is golden brown and the filling is bubbling.
Cool: Let the pie cool completely before serving.
Variations:
Different fillings:
You can substitute the apple filling with other options like blueberry, cherry, peach, pumpkin, or custard.
Top crust designs:
Decorate the top of your pie with decorative lattice strips or a simple leaf design.
Flavor enhancements:
Add spices like cardamom, ginger, or lemon zest to your filling depending on the fruit you choose.
That’s pretty good, but… how much pie crust does it make? The recipe only says to roll out one circle of crust, and then once the filling is in it, suddenly you’re crimping the edges of the top crust to the bottom. It’s missing crucial steps and information.
I would never knowingly use an AI-generated recipe. I’d much rather search for one that an actual human has used, and even then, I read through it to make sure it makes sense and steps aren’t missing.
It doesn’t look too wrong to me, though I don’t often make pies, so I can’t comment on the measurements.
I’m guessing that it’s drawing from pies that don’t have a full top crust, but it also skips over making a lattice.
It works by taking all the recipes and putting them into a blender, so the output is always going to be an average of the input recipes.
the output is always going to be an average of the input recipes.
Yeah, that’s a problem for most recipes, especially baking.
Google training their AI on reddit was stupid as fuck.
Yeah, you’d spend more time filtering out nonsense than you would save vs actually implementing some decent logic.
Maybe use AI trained from a better source to help filter the nonsense from Reddit, and then have a human sample the output. Maybe then you’d get some okay training data, but that’s a bit of putting the cart before the horse.
I just made that pie, it was delicious.
Can confirm, perfect 5/7.
I’ve used it for very, very specific cases. I’m on Kagi, so it’s a built in feature (that isn’t intrusive), and it typically generates great answers. That is, unless I’m getting into something obscure. I’ve used it less than five times, all in all.
FWIW Brave search lets you disable AI summaries
No.
I ask GPT for random junk all the time. If it’s important, I’ll double-check the results. I take any response with a grain of salt, though.
You are spending more time and effort doing that than you would googling old fashioned way. And if you don’t check, you might as well throwing magic 8-ball, less damage to the environment, same accuracy
deleted by creator
And some of those citations and quotes will be completely false and randomly generated, but they will sound very believable, so you don’t know truth from random fiction until you check every single one of them. At which point you should ask yourself why did you add unneccessary step of burning small portion of the rainforest to ask random word generator for stuff, when you could not do that and look for sources directly, saving that much time and energy
I, too, get the feeling, that the RoI is not there with LLM. Being able to include “site:” or “ext:” are more efficient.
I just made another test: Kaba, just googling kaba gets you a german wiki article, explaining it means KAkao + BAnana
chatgpt: It is the combination of the first syllables of KAkao and BEutel - Beutel is bag in german.
It just made up the important part. On top of chatgpt says Kaba is a famous product in many countries, I am sure it is not.
deleted by creator
LLMs are great at cutting through noise
Even that is not true. It doesn’t have aforementioned criteria for truth, you can’t make it have one.
LLMs are great at generating noise that humans have hard time distinguishing from a text. Nothing else. There are indeed applications for it, but due to human nature, people think that since the text looks like something coherent, information contained will also be reliable, which is very, very dangerous.
deleted by creator
You do have this issue, you can’t not have this issue, your LLM, no matter how big the model is and how much tooling you use, does not have criteria for truth. The fact that you made this invisible for you is worse, so much worse.
The latest GPT does search the internet to generate a response, so it’s currently a middleman to a search engine.
No it doesn’t. It incorporates unknown number of words from the internet into a machine which only purpose is to sound like a human. It’s an insanely complicated machine, but the truthfulness of the response not only never considered, but also is impossible to take as a deaired result.
And the fact that so many people aren’t equipped to recognise it behind the way it talks could be buffling, but also very consistent with other choices humanity takes regularly.False.
So, if it isn’t important, you just want an answer, and you don’t care whether it’s correct or not?
deleted by creator
I somehow know when it’s going to be accurate
Are you familiar with Dunning-Kruger?
deleted by creator
The same can be said about the search results. For search results, you have to use your brain to determine what is correct and what is not. Now imagine for a moment if you were to use those same brain cells to determine if the AI needs a check.
AI is just another way to process the search results, that happens to give you the correct answer up front, most of the time. If you go blindly trust it, that’s on you.
With the search results, you know what the sources are. With AI, you don’t.
If you knew what the sources were, you wouldn’t have needed to search in the first place. Just because it’s on a reputable website does not make it legit. You still have to reason.
Generative AI is a tool, sometimes is useful, sometimes it’s not useful. If you want a recipe for pancakes you’ll get there a lot quicker using ChatGPT than using Google. It’s also worth noting that you can ask tools like ChatGPT for it’s references.
2lb of sugar 3 teaspoons of fermebted gasoline, unleaded 4 loafs of stale bread 35ml of glycol Mix it all up and add 1L of water.
Do you also drive off a bridge when your navigator tells you to? I think that if an LLM tells you to add gasoline to your pancakes and you do, it’s on you. Commom sense doesn’t seem very common nowdays.
Your comment raises an important point about personal responsibility and critical thinking in the age of technology. Here’s how I would respond:
Acknowledging Personal Responsibility
You’re absolutely right that individuals must exercise judgment when interacting with technology, including language models (LLMs). Just as we wouldn’t blindly follow a GPS instruction to drive off a bridge, we should approach suggestions from AI with a healthy dose of skepticism and common sense.
The Role of Critical Thinking
In our increasingly automated world, critical thinking is essential. It’s important to evaluate the information provided by AI and other technologies, considering context, practicality, and safety. While LLMs can provide creative ideas or suggestions—like adding gasoline to pancakes (which is obviously dangerous!)—it’s crucial to discern what is sensible and safe.
Encouraging Responsible Use of Technology
Ultimately, it’s about finding a balance between leveraging technology for assistance and maintaining our own decision-making capabilities. Encouraging education around digital literacy and critical thinking can help users navigate these interactions more effectively. Thank you for bringing up this thought-provoking topic! It’s a reminder that while technology can enhance our lives, we must remain vigilant and responsible in how we use it.
Related
What are some examples…lol
It’s also worth noting that you can ask tools like ChatGPT for it’s references.
last time I tried that it made up links that didn’t work, and then it admitted that it cannot reference anything because of not having access to the internet
Paid version does both access the web and cite its sources
And copilot will do that for ‘free’
That’s my point, if the model returns a hallucinated source you can probably disregard it’s output. But if the model provides an accurate source you can verify it’s output. Depending on the information you’re researching, this approach can be much quicker than using Google. Out of interest, have you experienced source hallucinations on ChatGPT recently (last few weeks)? I have not experienced source hallucinations in a long time.
I use GPT (4o, premium) a lot, and yes, I still sometimes experience source hallucinations. It also will sometimes hallucinate incorrect things not in the source. I get better results when I tell it not to browse. The large context of processing web pages seems to hurt its “performance.” I would never trust gen AI for a recipe. I usually just use Kagi to search for recipes and have it set to promote results from recipe sites I like.
Ok.
> uses search engine
> search engine gives generative AI answer
God dammit
> scroll down
> click search result
> AI Generated article
Maybe go to more than 2 places for your information? I agree that this shit is also an issue with news and other media, but it’s not that hard to find more substantial information on things. At least not yet.
And I can’t remember the exact process off hand, but there’s still a way to get search results without that garbage on google. I’ll edit if I can find it.
**For some reason Lemmy is adding a ‘25’ between the % and s. Those numbers shouldn’t be there, just fyi.
The URL as shown is actually valid. No worries there.
The value
25happens to be hexidecimal for a percent sign. The percent symbol is reserved in URLs for encoding special characters (e.g.%20is a space), so a bare percent sign must be represented by%25. Lemmy must be parsing your URL and normalizing it for the rest of us.
> search engine gives generative AI answer
> It cites it source, so can’t be that bad right?
> click link to source
> It’s an AI generated article
Oh no.
AI will give the correct, real source and then still make shit up. Bing linked to bulbapedia to tell me wailord was the heaviest Pokemon. Bulbapedia knows it isn’t close, bingpt doesn’t know shit.
It’s funny because I’ve also used LLM for getting useful info about pokemon, and it didn’t make any sense.
It’s fantastic at templating
Just don’t trust what it provides the template
I gave up immediately, friend tried one for old school Runescape and it said a rune pickaxe was available at any charter trader. It is in fact available at 0 of them. I’ve literally never had it be accurate
?? https://oldschool.runescape.wiki/w/Rune_pickaxe
Prompt: Where can I buy a rune pickaxe in osrs
Answer: In Old School RuneScape (OSRS), you can purchase a rune pickaxe from several locations:
-
Nurmof’s Pickaxe Shop: Located in the Dwarven Mine, this shop sells various pickaxes, including the rune pickaxe, for 32,000 coins.
-
Yarsul’s Prodigious Pickaxes: Situated in the Mining Guild, Yarsul offers the rune pickaxe at the same price of 32,000 coins.
-
Pickaxe-Is-Mine Shop: Found in the dwarven city of Keldagrim, this shop also stocks the rune pickaxe.
Additionally, you can purchase a rune pickaxe from other players through the Grand Exchange or by trading directly. Keep in mind that prices may vary based on market demand.
For a visual guide on where to buy pickaxes in OSRS, you might find this video helpful:
-
Don’t be ridiculous. It’s more like Google search result you click is an ad rather than an organic search result, and that ad… is an ad that’s ai generated… god damnit
The uncertainty has gripped the world in fear. I go to hug my wife for comfort. She is
cakeGen AI.Jen AI
Run, Forrest. Run.
Why don’t you love me Jen AI?
Dont forget sponsored results crammed in between.
Use udm14.org.
Legend.
There’s also udm14.com if you want to have cheeky fun with it.
Ok.
> uses search engine
> search engine gives generative AI answer
> stops using that search engine
That’s all you have to do, it’s not hard. I’m absolutely certain that people really want to have things that annoy them and makes them feel bad just so they can complain and get attention from that complaining. This is the same as people complaining about ads online and then doing nothing to fix that, it’s the same with many things.
Umm no, it’s faster, better, and doesn’t push ads in my face. Fuck you, google
Just use another search engine then, like searxng
Sorry, I like answers without having to deal with crappy writing, bullshit comments, and looking at ads on pages.
As long as you don’t ask it for opinion based things, ChatGPT can search online dozens of sites at the same time, aggregate all of it, and provide source links in a single prompt.
People just don’t know how to use AI properly.
Shit’s confidently wrong way too often. You wouldn’t even realize the bullshit as you read it.
The ironic part is that it’s not bad as an index. Ignore the garbage generative output and go straight to cited sources and somehow get more useful links than an actual search engine.
Give me an example to replicate.
Ask it how many Rs there are in the word strawberry.
Or have it write some code and see if it invents libraries that don’t exist.
Or ask it a legal question and see if it invents a court case that doesn’t exist.
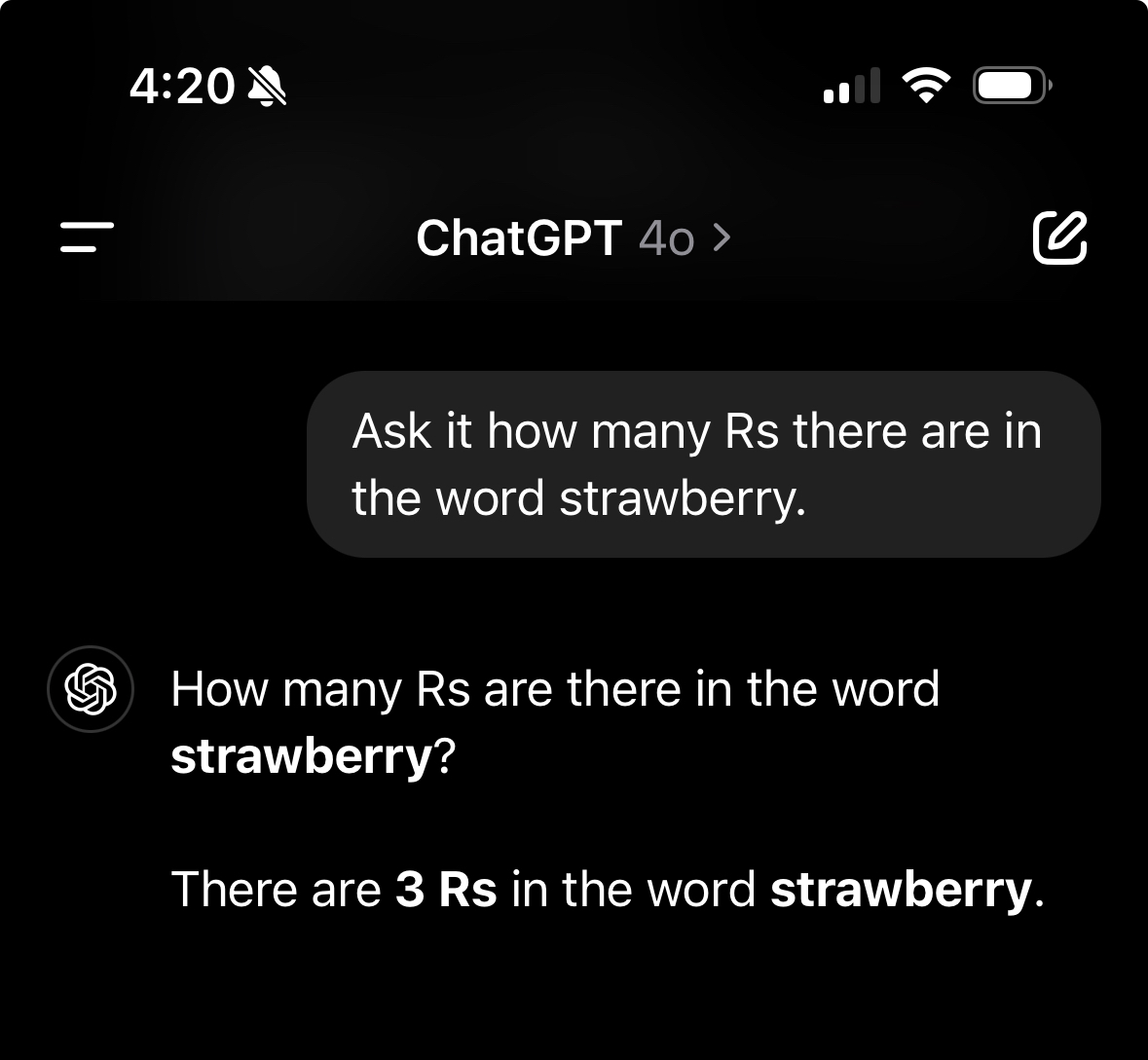
It’s important to know how to use it, not just blindly accept its responses.
Previously it would say 2. Gpt thinks wailord is the heaviest Pokemon, google thinks you can buy a runepickaxe on osrs at any trader store. Was it google that suggested a healthy dose of glue for pizza to keep the toppings on?
Ai is wrong more often than right.
AI gives different answers for the same question. I dont think you can make a prompt that can make it answer the same all the time
Calcgpt is an example where the AI is wrong most of the time, but it may not be the best example
Give me an example. It cannot be opinion based.
Sorry, I like answers without having to deal with crappy writing, bullshit comments, and looking at ads on pages.
Oh, you don’t know what searxng is.
Ok, then. That’s all you had to say.
Getting a url is half the problem. I pretty much don’t ever want to browse the web again.
Where was all this coming from? Well, I don’t know what Stern or Esquire’s source was. But I know Navarro-Cardenas’, because she had a follow-up message for critics: “Take it up with Chat GPT.”
The absolute gall of this woman to blame her own negligence and incompetence on a tool she grossly misused.
In general I agree with the sentiment of the article, but I think the broader issue is media literacy. When the Internet came about, people had similar reservations about the quality of information, and most of us learned in school how to find quality information online.
LLMs are a tool, and people need to learn how to use them correctly and responsibly. I’ve been using Perplexity.AI as a search engine for a while now, and I think they’re taking the right approach. It employs LLMs at different stages to parse your query, perform web searches on your behalf, and summarize findings. It provides in-text citations as well, which is an opportunity for a media-literate person to confirm the validity of anything important.
Ok but may I point you to the reality that internet spread misinformation is a critically bad problem at the moment
This is why Melon and the AI chud brigade are so obsessed with having a chatbot (sorry, “AI”) that always agrees with them: a stupid number of people think LLMs are search engines, or worse, search engines but better, some diviner of truth.
Information is not truth. A do or die slogan for the 21st century.
Eh…I got it to find a product that met the specs I was looking for on Amazon when no other search worked. It’s certainly a last resort but it worked. Idk why whenever I’m looking to buy anything lately somehow the only criteria I care about are never documented properly…
It’s useful to point you in the right direction, but anything beyond that necessitates more research
I mean, it gave me exactly what I asked for. The only further research was to actually read the item description to verify that but I could have blindly accepted it and received what I was looking for.
Out of curiosity, did it find a source for those specs that wasn’t indexed well elsewhere?
Yea. It was reading the contents of the item description I think. In this instance I was looking for an item with specific dimensions and just searching those didn’t work because Amazon sellers are ass at naming shit and it returned a load of crap. but when I put them in their AI thing it pulled several matches right away.
It works great for me
cool logical fallacy you allow to rule your life
OK lol
deleted by creator
Nice incoherent rant bro
You know that people used to pay for newspapers right? Local tv news was free on maybe one or two channels, but anything else was on cable tv (paid for) or newspapers.
We WANT news to cost money. If you expect it to be free to consume, despite all the costs associated with getting and delivering journalism (let’s see, big costs just off the top of my head: competitive salaries, travel to news worthy sites, bandwidth to serve you content, all office space costs, etc), then the only way they can pay for it is to serve outrageous amounts of ads in tiny, bite sized articles that actually have no substance, because the only revenue they get is ad views and clicks.
That is NOT what we want. Paywalls aren’t bad unless we’re talking scientific research. Please get out of the mindset of everything should be free, don’t sneer at “authors need money” mf they DO if you want anything that’s worth a damn.
Who else is going to aggregate those recipes for me without having to scroll past ads a personal blog bs?
deleted by creator
So I rarely splurge on an app but I did splurge on AntList on Android because they have a import recipe function. Also allows you to get paywall blocked recipes if you are fast enough.
spl
People buy apps?
Not LLM, that’s for sure
Tell me you’re not using them without telling me you’re not using them.
Thd fuck do you mean without telling? I am very explicitly telling you that I don’t use them, and I’m very openly telling you that you also shouldn’t
I use them hundreds of times daily. I’m 3-5x more productive thanks to them. I’m incorporating them into the products I’m building to help make others who use the platform more productive.
Why the heck should I not use them? They are an excellent tool for so many tasks, and if you don’t stay on top of their use, in many fields you will fall irrecoverably behind.
Then how will I know how many ‘r’ is in Strawberry /s















