
cross-posted from: https://discuss.tchncs.de/post/13814482
I just noticed that
ezacan now display total disk space used by directories!I think this is pretty cool. I wanted it for a long time.
There are other ways to get the information of course. But having it integrated with all the other options for listing directories is fab.
ezahas features like--git-awareness,--treedisplay, clickable--hyperlink, filetype--iconsand other display, permissions, dates, ownerships, and other stuff. being able to mash everything together in any arbitrary way which is useful is handy. And of course you can--sort=sizedocs:
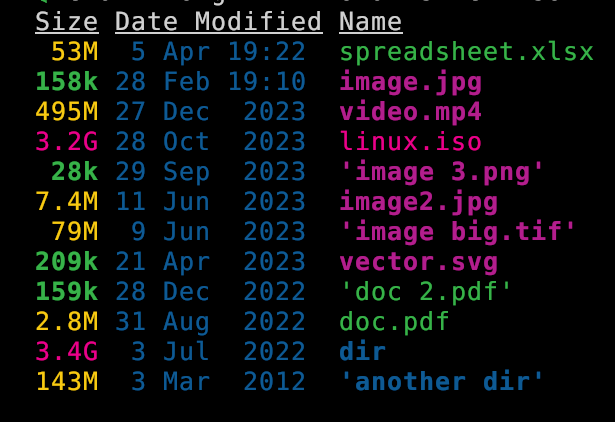
--total-size show the size of a directory as the size of all files and directories inside (unix only)It also (optionally) color codes the information. Values measures in kb, mb, and gb are clear. Here is a screenshot to show that:
eza --long -h --total-size --sort=oldest --no-permissions --no-user
Of course it take a little while to load large directories so you will not want to use by default.
Looks like it was first implemented Oct 2023 with some fixes since then. (Changelog). PR #533 - feat: added recursive directory parser with `–total-size` flag by Xemptuous
I just tested this and the reported sizes with
eza -l --total-sizeare wrong for me. I compare it todu --human-readable --apparent-size --all --max-depth 1and with opening properties in my Dolphin filemanager. Some are way off. In exampleduand Dolphin report for a certain projects folder of mine “149M”, whileezareports “184M”.hmm I didn’t think to actually test the results. But now that i do, I get same sort of descrepency.
How about this?
eza --long -h --total-size --sort=size --no-permissions --no-user --no-time -a --blocksize --binarythat works in a couple test directories with the column
Blocksize.Also it might (??) be ignoring according to your
gitignoreif that is relevant? Or behaving differently wrt symlinks?Seems like the default behavior should be whatever is most expected, standard and obvious. Or else give user a hint.
I find this in the repo, is t relevant?: bug: Inconsistent Size Display in `exa` Command for Large Files (1024 vs. 1000 Conversion) · Issue #519.
don’t forget
eza --version. I find it is not updated quickly in every distro. See changelog; it looks like there might have been a relevant update as recently as[] - 2024-03-06. Actual my system is only updated to0.17.3now that I check this too.With
--binaryoption I get size of174Miineza. Experimenting with some other options didn’t help. If something is ignored (maybe gitignore), then it would be thatduAND Dolphin filemanager would ignore those files, andezawould not. Which its hard to believe for me. I also deleted the .gitignore and .git files/folder to see if it makes any difference and no, it did not.The only thing I can think of is maybe something going on with link files, but no idea how or what to test for here.
well I guess a way to test would be to create a new directory and copy or create some files into it rather than using a working directory where there are unknown complexities. IIRC
ddcan create files according to parameters.Start with a single file in a normal location and see how to get it to output the correct info and complicate things until you can find out where it breaks.
That’s what I would do, but maybe a dev would have a more sophisticated method. Might be worth while to read the PR where the feature was introduced.
Also kind of a shot in the dark but do you have an ext4 filesystem? I have been dabbling with btrfs lately and it leads to some strange behaviors. Like some problems with rsync. Ideally this tool would be working properly for all use cases but it’s new so perhaps the testing would be helpful. I also noticed that this feature is unix only. I didn’t read about why.
it would be that
duAND Dolphin filemanager would ignore those files, andezawould not. Which its hard to believe for me.Although only 1 of various potential causes, I don’t think it is implausible on its face.
duprobably doesn’t know aboutgitat all right? If nautilus has a VCS extension installed I doubt it would specifically ignore for the purposes of calculating file size.I have found a lot of these rust alternatives ignore
.gitand other files a little too aggressively for my taste. Bothfd(find), andag(grep) require 1-2 arguments to include dotfiles,git-ignored and other files. There are other defaults that I suppose make lots of sense in certain contexts. Often I can’t find something I know is there and eventually it turns out it’s being ignored somehow.About the gitignore stuff of Rust tools: Its the opposite for my results, in that eza has bigger size. And the fact that the independent program Dolphin filemanager aligns with the output of the standard du tool (for which I don’t have a config file I think) speaks for being the more correct output.
Ok so I found it: Hardlinks
$ \ls -l total 9404 -rwxr-xr-x 2 tuncay tuncay 4810688 5. Apr 10:47 build-script-main -rwxr-xr-x 2 tuncay tuncay 4810688 5. Apr 10:47 build_script_main-947fc87152b779c9 -rw-r--r-- 1 tuncay tuncay 2298 5. Apr 10:47 build_script_main-947fc87152b779c9.d $ md5sum * 6ce0dea7ef5570667460c6ecb47fb598 build-script-main 6ce0dea7ef5570667460c6ecb47fb598 build_script_main-947fc87152b779c9 68e78f30049466b4ca8fe1f4431dbe64 build_script_main-947fc87152b779c9.dI went down into the directories and compared some outputs until I could circle it down (is it called like that?). Look at the number
2, which means those files are hardlink. Their md5 checksum are identical. So its what I was thinking all along, some kind of linking weirdness (which in itself is not weird at all). Soezais not aware of hardlinks and count them as individual files, which is simply wrong, from perspective of how much space those files occupy. The file exists once on the disk and requires only one time space.EDIT: BTW sorry that my replies turned your news post into a troubleshooting post. :-(
For my part I think all this troublefinding and troublesolving is a great use of a thread. :D Especially if it gets turned into a bug report and eventually PR. I had a quick look in the repo and I don’t see anything relevant but it could be hidden where I can’t see it. Since you’ve already gone and found the problem it would be a shame to leave it here where it’ll never be found or seen. Hope you will send to them.
I also reproduce the bug by moving an ISO file into a directory then hardlinking it in the same dir. Each file is counted individually and the dir is 2x the size it should be! I can’t find any way to fix it.
The best I can come up with is to show the links but it only works when you look at the linked file itself:
$ eza --long -h --total-size --sort=oldest --no-permissions --no-user --no-time --tree --links LinuxISOs Links Size Name 1 3.1G LinuxISOs 2 1.5G ├── linux.iso 2 1.5G └── morelinux.isoIf you look further up the filetree you could never guess. (I will say again that my distro is not up to date with the latest release and it is possible this is already fixed.)
This should be an option. In
dua-cli, another one of the other rust terminal tools I love, you can choose:$ dua LinuxISOs 0 B morelinux.iso 1.43 GiB linux.iso 1.43 GiB total $ dua --count-hard-links LinuxISOs 1.43 GiB linux.iso 1.43 GiB morelinux.iso 2.86 GiB totalBTW I actually did a bug report. :-) -> https://github.com/eza-community/eza/issues/923
So nothing wasted. Without your post I would not be curious to test this and who knows, maybe it gets fixed or an option to handle it.
Nice! I’m sure they will appreciate your thorough report.
I wonder if they also plan to make an option about crossing filesystem boundaries. I have seen it commonly in this sort of use case.
Maybe all this complexity this is the reason why total dir size has not previously been integrated into this kind of tool. (Notable exception:
lsdif you are interested.) I really hope the development persists though because being able to easily manipulate so many different kinds of information about the filesystem without spending hours/days/weeks/years creating bespoke shell scripts is super handy.
this looks like one is using the SI 1000-based units, instead of the binary 1024-based. im pretty sure
duhas a--sioption.the
B(for bytes) is omitted, so it each is ambiguous to whether itsMiB(mebibytes – binary) orMB(megabytes – SI).i may be wrong on the technicals but u get the jist.
The difference is too large for that. 184 MB is 176 MiB not 149.
No, the difference is way too high to explain it like this, there is no way that 1024 vs 1000 base could explain an increase of approx. “35M” for a “149M” directory. Other folders are much closer like “20K” and “20K” or =or “44M” vs “45M”. Also as said Dolphin filemanager reports the same output as
du. I even testedduwith--sioption, which power of 1000 instead 1024 (I’m pretty sureezadoes it correctly with 1024, so this is not necessary option to compare anyway).No, @lseif@sopuli.xyz is correct.
I just did a test using
dd- I created 100 files of exactly 1 MiB each (1048576 bytes).dureported the size as “100M” as expected, whereasezareported it as “105M” - which is what you’d get if you divided 104857600 by 1000000 (= 104.8576 or 105M if you round it off).He is wrong, as I explained it multiple times that this is not the issue here. Install
ezaand compare toduand possibly some other application that reports the directory size. The difference in filesize cannot be explained by 1000 vs 1024 base. Do the math if you don’t believe me.ezais reporting false directory size for me, unless there is an explanation.[Desktop]$ du --human-readable --apparent-size --all --max-depth 1 ./trampoline 518 ./trampoline/src 148M ./trampoline/target 1,1M ./trampoline/doc 8 ./trampoline/.gitignore 26K ./trampoline/.git 330 ./trampoline/Cargo.toml 2,1K ./trampoline/Cargo.lock 149M ./trampoline [Desktop]$ du --human-readable --apparent-size --all --max-depth 1 --si ./trampoline 518 ./trampoline/src 155M ./trampoline/target 1,2M ./trampoline/doc 8 ./trampoline/.gitignore 27k ./trampoline/.git 330 ./trampoline/Cargo.toml 2,2k ./trampoline/Cargo.lock 157M ./trampoline [Desktop]$ eza -l --total-size --no-permissions --no-user ./trampoline 2,1k 25 Feb 21:36 Cargo.lock 330 4 Mär 09:21 Cargo.toml 1,1M 5 Apr 12:34 doc 518 5 Apr 12:49 src 183M 4 Apr 20:26 targetAnd for reference Dolphin the filemanager of KDE Plasma reports
149,1 MiB (156.366.443), which aligns withduwithout using--sioption. Even the one folder “target” is at183Mwitheza(which is the biggest folder in that directory anyway).I was talking about the 1000 vs 1024 issue, do the dd test yourself and it’s easy to verify that he was right.
As for the specific descrepancy that you’re seeing, lots of things can throw off a file size calculation - symlinks, sparse files, reflinks, compression etc. Since you’re the only one with access to your files, you’ll need to investigate and come to a conclusion yourself (and file a bug report if necessary).
Could it be this AND block size vs actual used size?
Off topic, but maybe someone will appreciate this. I wrote a function to get the size of contents of a dir a while back. It has a couple of dependencies (
gc,gwcat a glance), but should be fairly portable. The results are sorted from greatest to least as shown in the screenshot.function szup() { description=' #: Title: szup #: Synopsis: sort all items within a directory according to size #: Date: 2016-05-30 #: Version: 0.0.5 #: Options: -h | --help: print short usage info #: : -v | --version: print version number ' funcname=$(echo "$description" | grep '^#: Title: ' | sed 's/#: Title: //g') version=$(echo "$description" | grep '^#: Version: ' | sed 's/#: Version: //g') updated="$(echo "$description" | grep '^#: Date: ' | sed 's/#: Date: //g')" function usage() { printf "\n%s\n" "$funcname : $version : $updated" printf "%s\n" "" } function sortdir() { Chars="$(printf " %s" "inspecting " "$(pwd)" | wc -c)" divider===================== divider=$divider$divider$divider$divider format=" %-${Chars}.${Chars}s %35s\n" totalwidth="$(ls -1 | /usr/local/bin/gwc -L)" totalwidth=$(echo $totalwidth | grep -o [0-9]\\+) Chars=$(echo $Chars | grep -o [0-9]\\+) if [ "$totalwidth" -lt "$Chars" ]; then longestvar="$Chars" else longestvar="$totalwidth" fi shortervar=$(/Users/danyoung/bin/qc "$longestvar"*.8) shortervar=$(printf "%1.0f\n" "$shortervar") echo "$shortervar" printf "\n %s\n" "inspecting $(pwd)" printf " %$shortervar.${longestvar}s\n" "$divider" theOutput="$(du -hs "${theDir}"/* | gsort -hr)" Condensed="$(echo -n "$theOutput" | awk '{ print $1","$2 }')" unset arr declare -a arr arr=($(echo "$Condensed")) Count="$(echo "$(printf "%s\n" "${arr[@]}")" | wc -l)" Count=$((Count-1)) for i in $(seq 1 $Count); do read var1 var2 <<< "$(printf "%s\n" "${arr[$i]}" | sed 's/,/ /g')" printf " %5s %-16s\n" "$var1" "${var2//\/*\//./}" done echo } case "$1" in -h|--help) usage return 0 ;; *) : ;; esac if [ -z "$1" ]; then oldDir="$(pwd)" cd "${1}" local theDir="$(pwd)" sortdir cd "$oldDir" return 0 else : oldDir="$(pwd)" cd "${1}" local theDir="$(pwd)" sortdir cd "$oldDir" return 0 fi }``` Screenshot isn't working. I'll reply to this with it.Is this effectively the same as:
du -hs * | sort -h?Hahaha. I may have spent a lot of time creating a script to implement functionality that was already there.
du -hs * | sort -h -r, I guess.
Thanks! I always appreciate another tool for this. I tried to run it but have dep issues.
What is
gwc? I can’t find a package by that name nor is it included that I can see.Websearch finds GeoWebCache, Gnome Wave Cleaner, GtkWaveCleaner, several IT companies… nothing that looks relevant.
edit: also stumped looking for
gsort. it seems to be associated with something called STATA which is statistical analysis software. Is that something you are involved with maybe running some special stuff on your system?PS you missed a newline at the end before closing the code block which is why the image was showing up as markdown instead of displaying properly.
Change:
}```to:
} ```Aha with the new line! Thank you!
I believe
gwcandgsortare part ofcoreutilsbased on this:$ gwc --help Usage: gwc [OPTION]... [FILE]... or: gwc [OPTION]... --files0-from=F Print newline, word, and byte counts for each FILE, and a total line if more than one FILE is specified. A word is a nonempty sequence of non white space delimited by white space characters or by start or end of input. With no FILE, or when FILE is -, read standard input. The options below may be used to select which counts are printed, always in the following order: newline, word, character, byte, maximum line length. -c, --bytes print the byte counts -m, --chars print the character counts -l, --lines print the newline counts --files0-from=F read input from the files specified by NUL-terminated names in file F; If F is - then read names from standard input -L, --max-line-length print the maximum display width -w, --words print the word counts --total=WHEN when to print a line with total counts; WHEN can be: auto, always, only, never --help display this help and exit --version output version information and exit GNU coreutils online help: <https://www.gnu.org/software/coreutils/> Full documentation <https://www.gnu.org/software/coreutils/wc> or available locally via: info '(coreutils) wc invocation'

Why does ls need a replacement?
What does this do that ls cannot?
It’s subjective, but it looks better
Function is what I want.
good design is a function on its own
better defaults, icons, color coding, and other optional views improve on the functions of the default ls
It’s written in a safe language
Does it use safe development practices though? Or is mainstream Rust development npm leftpad all over again with developers dumpster diving for dependencies to make their lives easier and more productive.
There is potentially a price to pay for colour ansi graphics and emoji and it comes in the form of a large tree of often trivial third party crates of unknown quality which could potentially contain harmful code. Is it all audited? Do I want it on a company server with customer data or even on a desktop with my own data?
The various gnu and bsd core utils are maintained by their projects and are self contained without external dependencies and have history. There are projects rewriting unix core utils in Rust (uutils) that seem to be less frivolous which are more to my taste. Most traditional unix utils have very limited functionality and have been extensively analyzed over many years by both people and tools which offsets a lot of the deficiencies of the implementation language.
I am inclined to agree with you. See my comment in cross post of this thread.
I’m just a home admin of my own local systems and while I try to avoid doing stuff that’s too wacky, in the context I don’t mind playing a bit fast n loose. If I screw it up, the consequences are my own.
At work, I am an end user of systems with much higher grade of importance to lots of people. I would not be impressed to learn there was a bunch of novel bleeding edge stuff running on those systems. Administering them has a higher burden of care and responsibility and I expect the people in charge to apply more scrutiny. If it’s screwed up, the consequences are on a lot of people with no agency over the situation.
Just like other things done at small vs large scale. Most people with long hair don’t wear a hairnet when cooking at home, although it is a requirement in some industrial food prep situations. Most home fridges don’t have strict rules about how to store different kinds of foods to avoid cross contamination, nor do they have a thermometer which is checked regularly and logged to show the food is being stored appropriately. Although this needs to be done in a professional context. Pressures, risks and consequences are different.
To summarize: I certainly hope sysadmins aren’t on here installing every doohicky some dumbass like me suggests on their production systems. :D
there’s no such thing as safe language. People sent spaceships to moon with assembly. But there is one such thing as undereducated bootcamp grad developer.
You’re both right!
We have tried the “sufficiently experienced and disciplined developer” approach for decades and it just doesn’t work.
Not sure that really applies here since ls is usually a shell built-in so you can’t exactly uninstall it, not to mention all this feature creep probably means exa/eza has a much larger attack surface.
aside from the subject of the post: the ones I miss when it’s not available are git status/ignoring, icons, tree, excellent color coding.
Here I cloned the
ezarepo and made some random changes.eza --long -h --no-user --no-time --almost-all --git --sort=date --reverse --icons
Made some more changes and then combine
gitandtree, something I find is super helpful for overview:eza --long -h --no-user --no-time --git --sort=date --reverse --icons --tree --level=2 --git-ignore --no-permissions --no-filesize
(weird icons are my fault for not setting up fonts properly in the terminal.)
Colors all over the place are an innovation that has enabled me to use the terminal really at all. I truly struggle when I need to use b&w or less colorful environments. I will almost always install
ezaon any device even something like a router that needs to be lean. It’s not just pretty and splashy but it helps me correctly comprehend the information.I’d never want to get rid of
lsand I don’t personally alias it to toezabecause I always want to have unimpeded access to the standard tooling. But I appreciate having a few options to do the same task in slightly different ways. And it’s so nice to have all the options together in one application rather than needing a bunch of scripts and aliases and configurations. I don’t think it does anything that’s otherwise impossible but to get on with life it is helpful.Not sure I could get with the huge string of arguments, That needs to be shortened to follow the ls style of stacking letters behind minimal “-”
Does look good but I prefer function to form.
Interesting though
So, exa became eza. Thanks. https://github.com/ogham/exa
exa is unmaintained, use the fork eza instead. (This repository isn’t archived because the only person with the rights to do so is unreachable).
Oh, I had no idea, time to change some aliases
Some of the distros actually just included an alias from
exatoezawhen the project forked. I didn’t even realize I was usingezafor a long time!
Awesome tool! If you use it with nerdfonts, you can have nice icons too!
Note: it is not a 1:1 replacement for
ls! Wait for uutils to be completed, and then start to use it.Off topic, but maybe someone will appreciate this. I wrote a function to get the size of contents of a dir a while back. It has a couple of dependencies (
gc,gwcat a glance), but should be fairly portable (correct paths for your system). The results are sorted from greatest to least as shown in the screenshot. The purpose was to be able to see directory sizes, which is the topic of this post, so I figured I’d share.Hope it’s useful to someone. Free to modify as desired.
function szup() { description=' #: Title: szup #: Synopsis: sort all items within a directory according to size #: Date: 2016-05-30 #: Version: 0.0.5 #: Options: -h | --help: print short usage info #: : -v | --version: print version number ' funcname=$(echo "$description" | grep '^#: Title: ' | sed 's/#: Title: //g') version=$(echo "$description" | grep '^#: Version: ' | sed 's/#: Version: //g') updated="$(echo "$description" | grep '^#: Date: ' | sed 's/#: Date: //g')" function usage() { printf "\n%s\n" "$funcname : $version : $updated" printf "%s\n" "" } function sortdir() { Chars="$(printf " %s" "inspecting " "$(pwd)" | wc -c)" divider===================== divider=$divider$divider$divider$divider format=" %-${Chars}.${Chars}s %35s\n" totalwidth="$(ls -1 | /usr/local/bin/gwc -L)" totalwidth=$(echo $totalwidth | grep -o [0-9]\\+) Chars=$(echo $Chars | grep -o [0-9]\\+) if [ "$totalwidth" -lt "$Chars" ]; then longestvar="$Chars" else longestvar="$totalwidth" fi shortervar=$(/Users/*********/bin/qc "$longestvar"*.8) shortervar=$(printf "%1.0f\n" "$shortervar") echo "$shortervar" printf "\n %s\n" "inspecting $(pwd)" printf " %$shortervar.${longestvar}s\n" "$divider" theOutput="$(du -hs "${theDir}"/* | gsort -hr)" Condensed="$(echo -n "$theOutput" | awk '{ print $1","$2 }')" unset arr declare -a arr arr=($(echo "$Condensed")) Count="$(echo "$(printf "%s\n" "${arr[@]}")" | wc -l)" Count=$((Count-1)) for i in $(seq 1 $Count); do read var1 var2 <<< "$(printf "%s\n" "${arr[$i]}" | sed 's/,/ /g')" printf " %5s %-16s\n" "$var1" "${var2//\/*\//./}" done echo } case "$1" in -h|--help) usage return 0 ;; *) : ;; esac if [ -z "$1" ]; then oldDir="$(pwd)" cd "${1}" local theDir="$(pwd)" sortdir cd "$oldDir" return 0 else : oldDir="$(pwd)" cd "${1}" local theDir="$(pwd)" sortdir cd "$oldDir" return 0 fi }``` 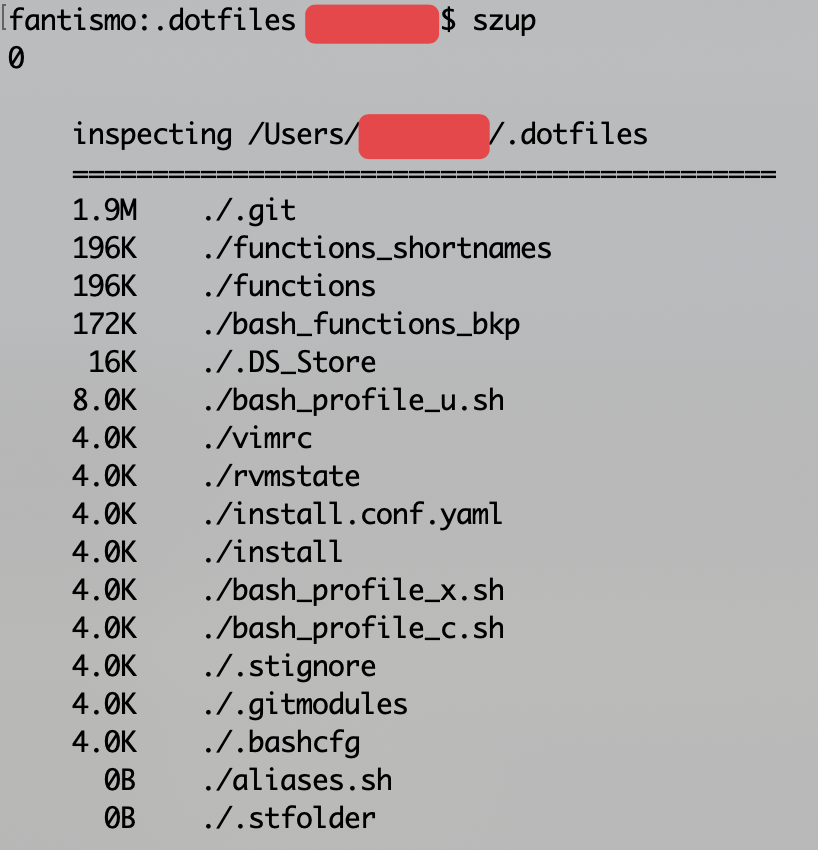ooops you commented similar/same twice. I think this one was a draft. :)



