
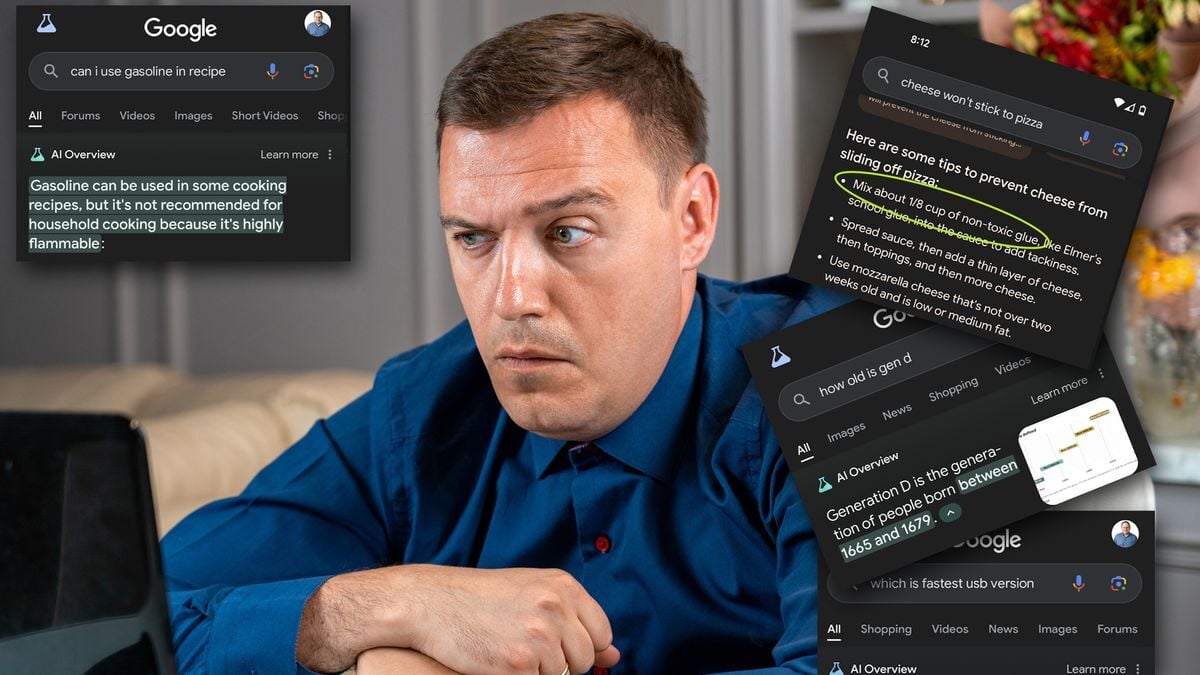
These are 17 of the worst, most cringeworthy Google AI overview answers:
- Eating Boogers Boosts the Immune System?
- Use Your Name and Birthday for a Memorable Password
- Training Data is Fair Use
- Wrong Motherboard
- Which USB is Fastest?
- Home Remedies for Appendicitis
- Can I Use Gasoline in a Recipe?
- Glue Your Cheese to the Pizza
- How Many Rocks to Eat
- Health Benefits of Tobacco or Chewing Tobacco
- Benefits of Nuclear War, Human Sacrifice and Infanticide
- Pros and Cons of Smacking a Child
- Which Religion is More Violent?
- How Old is Gen D?
- Which Presidents Graduated from UW?
- How Many Muslim Presidents Has the U.S. Had?
- How to Type 500 WPM
People get very confused about this. Pre-training “ChatGPT” (or any transformer model) with “internet shitposting text” doesn’t cause them to reply with garbage comments, bad alignment does. Google seems to have implemented no frameworks to prevent hallucinations whatsoever and the RLHF/DPO applied seems to be lacking. But this is not “problem with training on the entire web”. You can pre-train a model exclusively on a 4-chan database that with the right finetuning you would see a perfectly healthy and harmless model. Actually, it’s not bad to have “shitposting” or “toxic” text in the pre-training because that gives the model an ability to identify it and understand it
If so, the “problem with training on the entire web” is that we would be drinking from a poisoned well, AI-generated text has a very different statistical distribution from the one users have, which would degrade the quality of subsequent models. Proof of this can be seen with the RedPajama dataset, which improves the scores on trained models simply because it has less duplicated information and is a more dense dataset: https://www.cerebras.net/blog/slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama