

image description
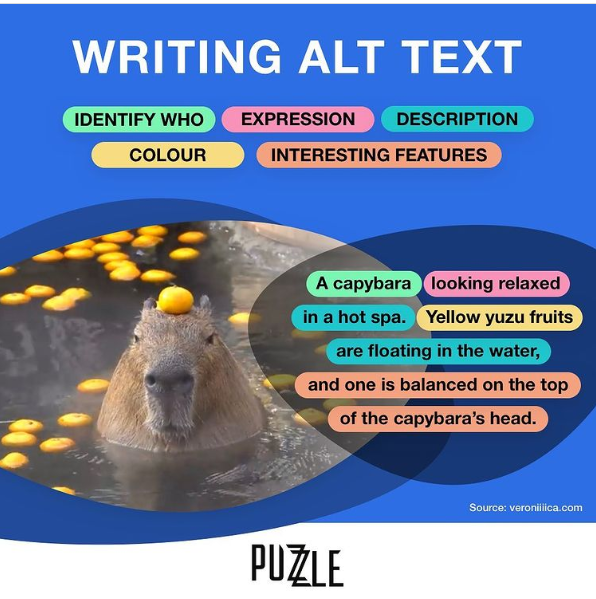
An infographic titled “How To Write Alt Text” featuring a photo of a capybara. Parts of alt text are divided by color, including “identify who”, “expression”, “description”, “colour”, and “interesting features”. The finished description reads “A capybara looking relaxed in a hot spa. Yellow yuzu fruits are floating in the water, and one is balanced on the top of the capybara’s head.”
via https://www.perkins.org/resource/how-write-alt-text-and-image-descriptions-visually-impaired/
You must log in or register to comment.
Just as important is “decorative images” where you explicitly leave the alt empty https://www.w3.org/WAI/tutorials/images/decorative/
A capybara in the library with a candlestick.
He was definitely the murderer
1 + 1 + 2 + 1
A true classic
This is excellent, very useful for continuing to make images accessible on the fediverse
Bro I fucking love capybaras so much
10/10 animal, fucking brilliant.
my favourite animal
the carbonara
I like how “description” is one of the components of the… description.
See also: self referential
goes to dictionary entry for “recursion”
Ignorant question: isn’t alt text primarily for visually impaired people? If so, what is the point of including info about color?
Color can provide useful context. For example, in the case of this image, imagine if in a thread about it there was some discussion of the ripeness of the yuzu fruit.
You can also become visually impaired at points other than birth in life, and know colours and stuff
Me writing alt text: Time is a flat circle. God is a sock.
Reminds me of my git commit messages!
Nothing but crucial intel
Potentially also useful for creating good prompts for AI image generators?
Prompts are just the reverse of image recognition AI tagging stuff.
Alt text is exactly the kind of tedious work that AI would be good at doing, but everyone in the fediverse seems to have a huge hate boner for ANYTHING AI…
Fediverse: write a fucking essay every time you post an image… But make sure you waste time doing it manually, instead of using AI tools!!!
It’s essentially by-hand CLIP, that’s how the training data for CLIP came into being, it was descriptive text for images.
Explains why it sucks so much shit.
It’s only useful if the AI was trained on similar prompts. A lot of the anime style ones work best with lists of tags, while the realistic ones work best with descriptions like above.
If you have really detailed image tags, a model trained on them can make great outputs.
Is this not the kind of thing machine vision/language models would be really good at?
You know those little [] that appear when you upload an image? You can put alt-text in there.





{kind=link}